View Jupyter notebook on the GitHub.
Get started#
![]()
This notebook contains the simple examples of time series forecasting pipeline using ETNA library.
Table of contents
Loading dataset
Plotting
Forecasting single time series
Naive forecast
Prophet
Catboost
Forecasting multiple time series
[1]:
!pip install "etna[prophet]" -q
[2]:
import warnings
warnings.filterwarnings(action="ignore", message="Torchmetrics v0.9")
[3]:
import pandas as pd
1. Loading dataset#
Let’s load and look at the dataset
[4]:
original_df = pd.read_csv("data/monthly-australian-wine-sales.csv")
original_df.head()
[4]:
| month | sales | |
|---|---|---|
| 0 | 1980-01-01 | 15136 |
| 1 | 1980-02-01 | 16733 |
| 2 | 1980-03-01 | 20016 |
| 3 | 1980-04-01 | 17708 |
| 4 | 1980-05-01 | 18019 |
etna_ts is strict about data format:
column we want to predict should be called
targetcolumn with datatime data should be called
timestampbecause etna is always ready to work with multiple time series, column
segmentis also compulsory
Our library works with the special data structure TSDataset. So, before starting anything, we need to convert the classical DataFrame to TSDataset.
Let’s rename first
[5]:
original_df["timestamp"] = pd.to_datetime(original_df["month"])
original_df["target"] = original_df["sales"]
original_df.drop(columns=["month", "sales"], inplace=True)
original_df["segment"] = "main"
original_df.head()
[5]:
| timestamp | target | segment | |
|---|---|---|---|
| 0 | 1980-01-01 | 15136 | main |
| 1 | 1980-02-01 | 16733 | main |
| 2 | 1980-03-01 | 20016 | main |
| 3 | 1980-04-01 | 17708 | main |
| 4 | 1980-05-01 | 18019 | main |
Time to convert to TSDataset!
To do this, we initially need to convert the classical DataFrame to the special format.
[6]:
from etna.datasets.tsdataset import TSDataset
df = TSDataset.to_dataset(original_df)
df.head()
[6]:
| segment | main |
|---|---|
| feature | target |
| timestamp | |
| 1980-01-01 | 15136 |
| 1980-02-01 | 16733 |
| 1980-03-01 | 20016 |
| 1980-04-01 | 17708 |
| 1980-05-01 | 18019 |
Now we can construct the TSDataset.
Additionally to passing dataframe we should specify frequency of our data. In this case it is monthly data.
[7]:
ts = TSDataset(df, freq="1M")
/Users/d.a.binin/Documents/tasks/etna-github/etna/datasets/tsdataset.py:147: UserWarning: You probably set wrong freq. Discovered freq in you data is MS, you set 1M
warnings.warn(
Oups. Let’s fix that by looking at the table of offsets in pandas:
[8]:
ts = TSDataset(df, freq="MS")
We can look at the basic information about the dataset
[9]:
ts.info()
<class 'etna.datasets.TSDataset'>
num_segments: 1
num_exogs: 0
num_regressors: 0
num_known_future: 0
freq: MS
start_timestamp end_timestamp length num_missing
segments
main 1980-01-01 1994-08-01 176 0
Or in DataFrame format
[10]:
ts.describe()
[10]:
| start_timestamp | end_timestamp | length | num_missing | num_segments | num_exogs | num_regressors | num_known_future | freq | |
|---|---|---|---|---|---|---|---|---|---|
| segments | |||||||||
| main | 1980-01-01 | 1994-08-01 | 176 | 0 | 1 | 0 | 0 | 0 | MS |
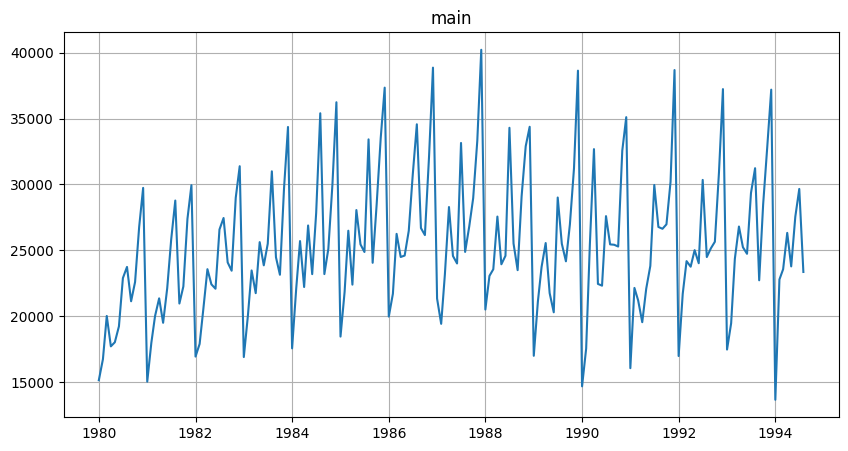
2. Plotting#
Let’s take a look at the time series in the dataset
[11]:
ts.plot()
3. Forecasting single time series#
Our library contains a wide range of different models for time series forecasting. Let’s look at some of them.
[12]:
warnings.filterwarnings("ignore")
Let’s predict the monthly values in 1994 for our dataset.
[13]:
HORIZON = 8
[14]:
train_ts, test_ts = ts.train_test_split(test_size=HORIZON)
3.1 Naive forecast#
We will start by using the NaiveModel that just takes the value from lag time steps before.
This model doesn’t require any features, so to make a forecast we should define pipeline with this model and set a proper horizon value.
[15]:
from etna.models import NaiveModel
from etna.pipeline import Pipeline
# Define a model
model = NaiveModel(lag=12)
# Define a pipeline
pipeline = Pipeline(model=model, horizon=HORIZON)
Let’s make a forecast.
[16]:
# Fit the pipeline
pipeline.fit(train_ts)
# Make a forecast
forecast_ts = pipeline.forecast()
Calling pipeline.forecast without parameters makes a forecast for the next HORIZON points after the end of the training set.
[17]:
forecast_ts.info()
<class 'etna.datasets.TSDataset'>
num_segments: 1
num_exogs: 0
num_regressors: 0
num_known_future: 0
freq: MS
start_timestamp end_timestamp length num_missing
segments
main 1994-01-01 1994-08-01 8 0
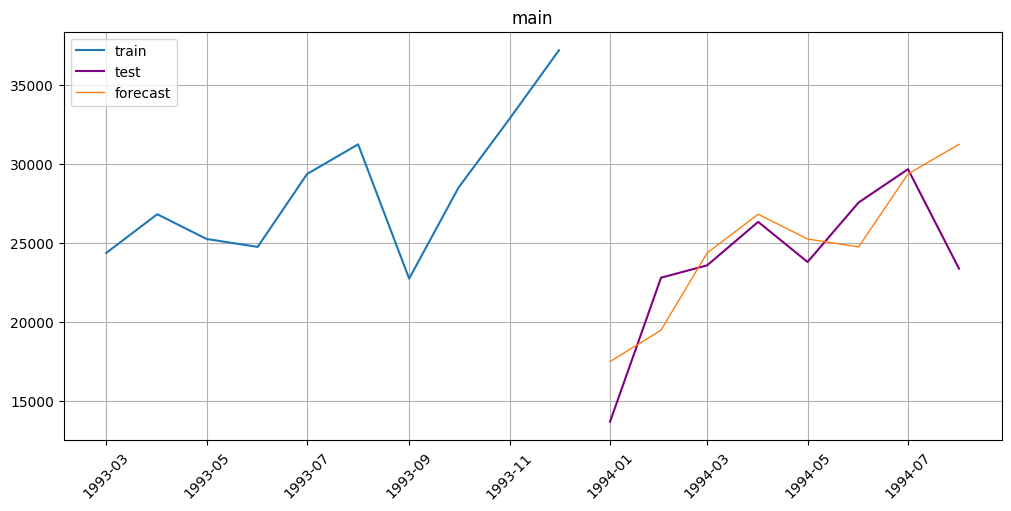
Now let’s look at the result metric and plot the prediction. All the methods already built-in in ETNA.
[18]:
from etna.metrics import SMAPE
smape = SMAPE()
smape(y_true=test_ts, y_pred=forecast_ts)
[18]:
{'main': 11.492045838249387}
[19]:
from etna.analysis import plot_forecast
plot_forecast(forecast_ts=forecast_ts, test_ts=test_ts, train_ts=train_ts, n_train_samples=10)
3.2 Prophet#
Now we can try to improve the forecast by using Prophet model.
[20]:
from etna.models import ProphetModel
# Define a model
model = ProphetModel()
# Define a pipeline
pipeline = Pipeline(model=model, horizon=HORIZON)
# Fit the pipeline
pipeline.fit(train_ts)
# Make a forecast
forecast_ts = pipeline.forecast()
12:21:11 - cmdstanpy - INFO - Chain [1] start processing
12:21:11 - cmdstanpy - INFO - Chain [1] done processing
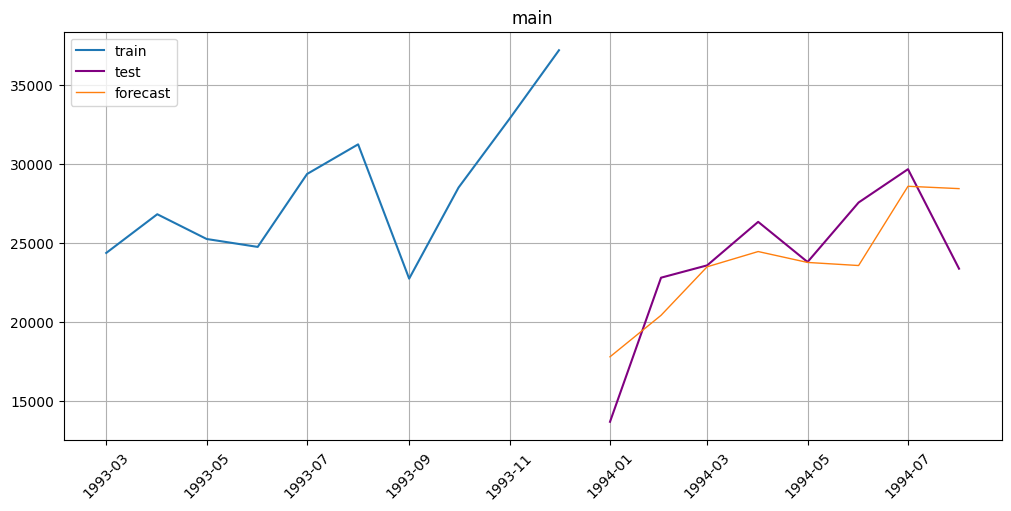
[21]:
smape(y_true=test_ts, y_pred=forecast_ts)
[21]:
{'main': 10.514961160817307}
[22]:
plot_forecast(forecast_ts=forecast_ts, test_ts=test_ts, train_ts=train_ts, n_train_samples=10)
3.3 Catboost#
Finally, let’s try the ML-model. This kind of models require some features to make a forecast.
3.3.1 Basic transforms#
ETNA has a wide variety of transforms to work with data, let’s take a look at some of them.
Lags
Lag transformation is the most basic one. It gives us some previous value of the time series. For example, the first lag is the previous value, and the fifth lag is the value five steps ago. Lags are essential for regression models, like linear regression or boosting, because they allow these models to grasp information about the past.
The scheme of working:
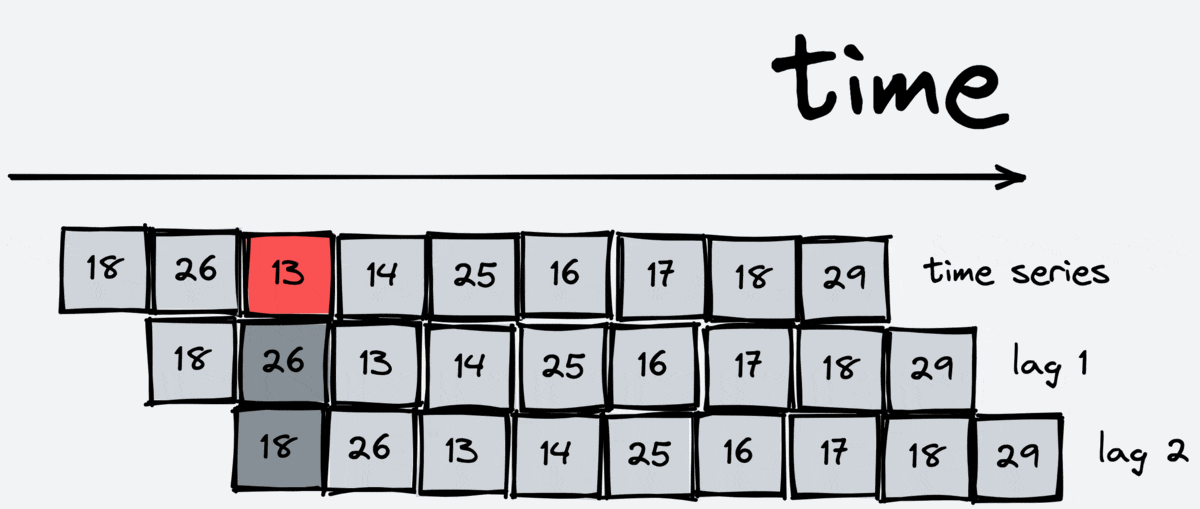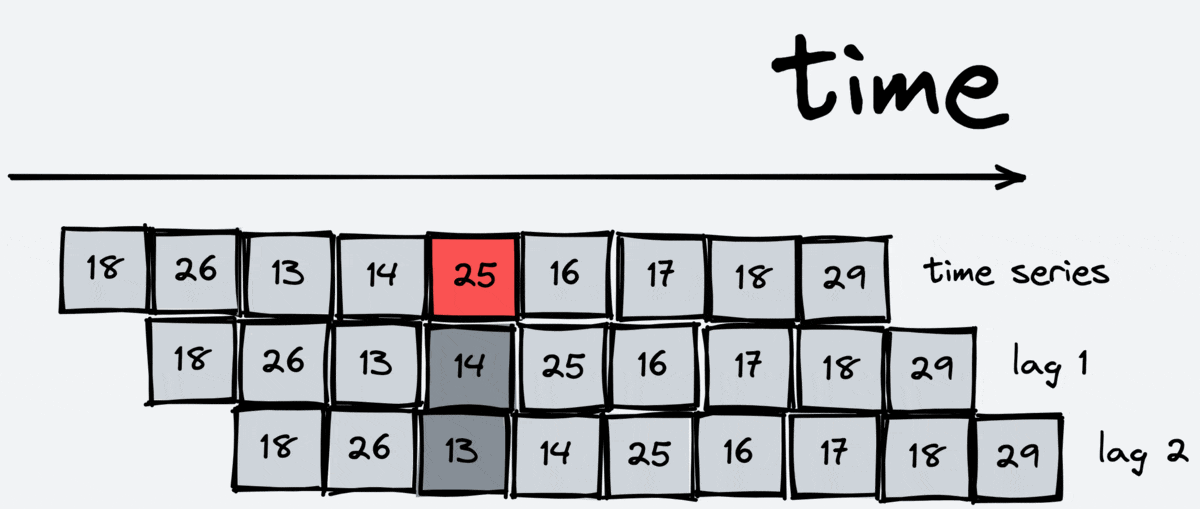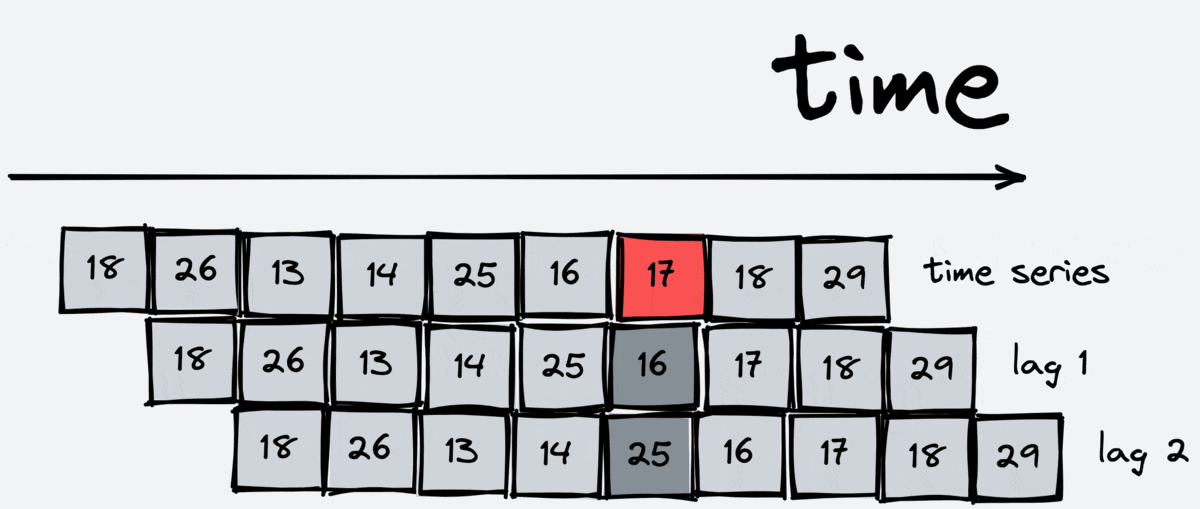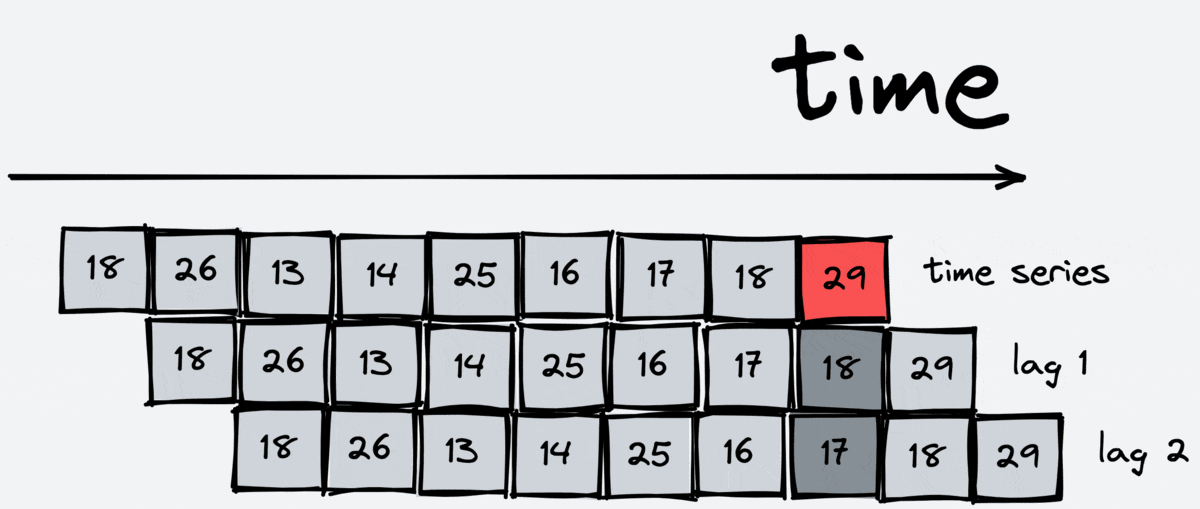
[23]:
from etna.transforms import LagTransform
lags = LagTransform(in_column="target", lags=list(range(HORIZON, 24)), out_column="lag")
There are some limitations on available lags during the forecasting. Imagine that we want to make a forecast for 3 step ahead. We can’t take the previous value when we make a forecast for the last step, we just don’t know the value. For this reason, you should use lags >= HORIZON when using a Pipeline.
Statistics
Statistics are another essential feature. It is also useful for regression models as it allows them to look at the information about the past but in different ways than lags. There are different types of statistics: mean, median, standard deviation, minimum and maximum on the interval.
The scheme of working:
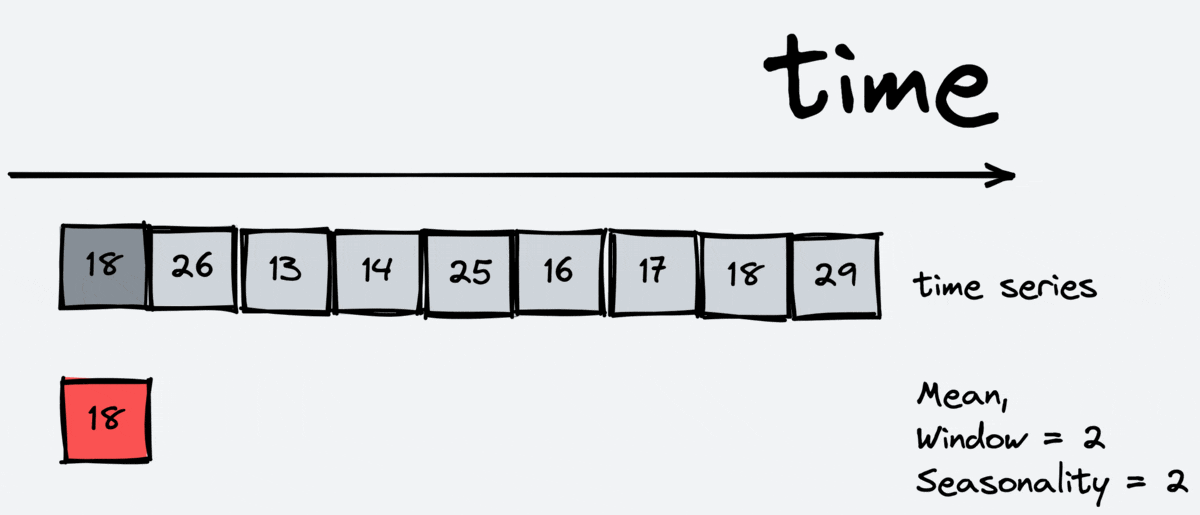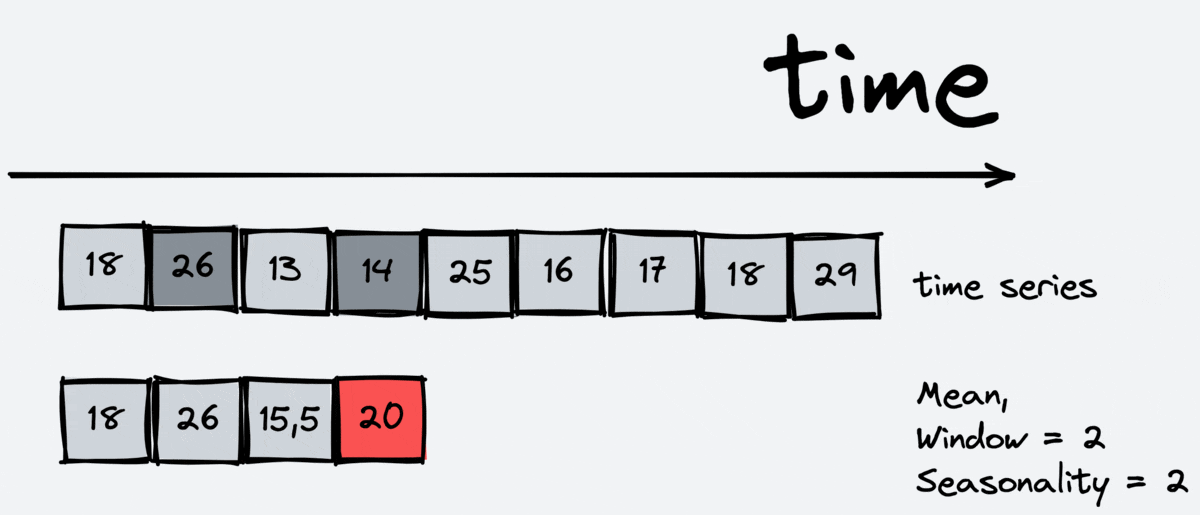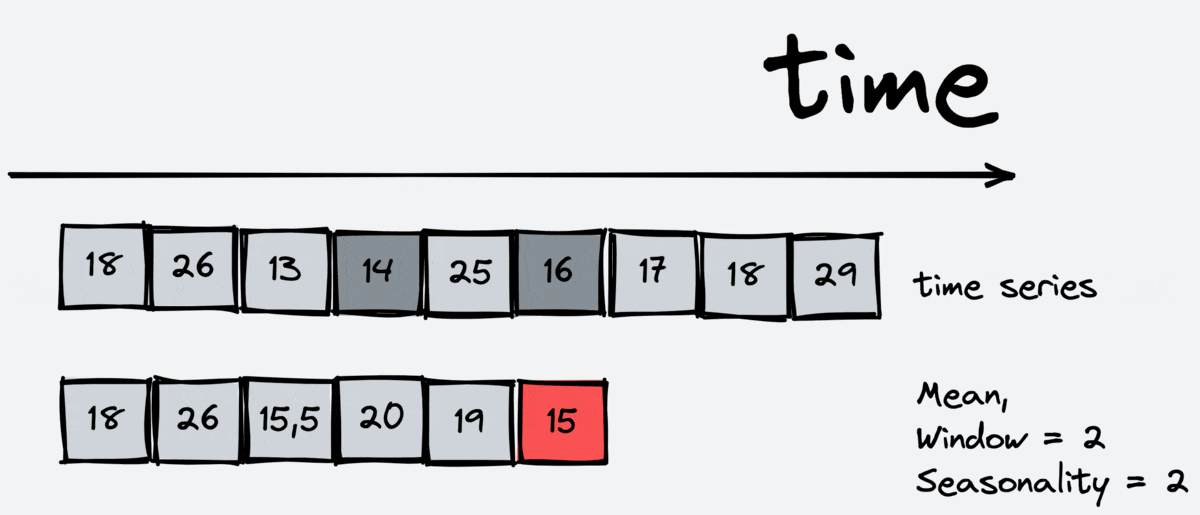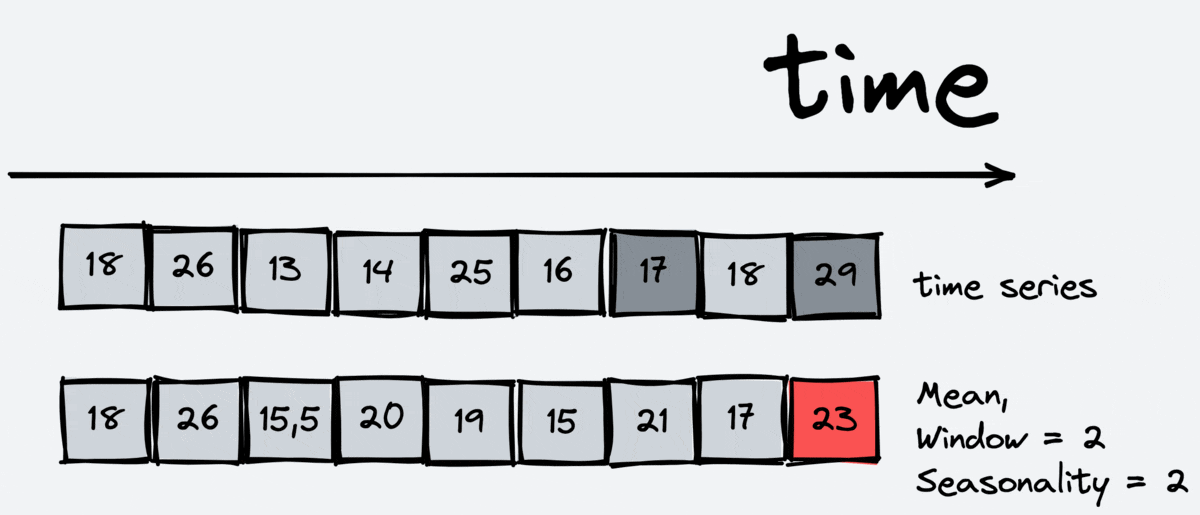
As we can see, the window includes the current timestamp. For this reason, we shouldn’t apply the statistics transformations to target variable, we should apply it to lagged target variable.
[24]:
from etna.transforms import MeanTransform
mean = MeanTransform(in_column=f"lag_{HORIZON}", window=12)
Dates
The time series also has the timestamp column that we have not used yet. But date number in a week and in a month, as well as week number in year or weekend flag can be really useful for the machine learning model. And ETNA allows us to extract all this information with DateFlagTransform.
[25]:
from etna.transforms import DateFlagsTransform
date_flags = DateFlagsTransform(
day_number_in_week=False,
day_number_in_month=False,
week_number_in_month=False,
month_number_in_year=True,
season_number=True,
is_weekend=False,
out_column="date_flag",
)
Logarithm
However, there is another type of transform that alters the column itself. We call it “inplace transform”. The easiest is LogTransform. It logarithms values in a column.
[26]:
from etna.transforms import LogTransform
log = LogTransform(in_column="target", inplace=True)
3.3.2 Forecasting#
Now let’s pass these transforms into our Pipeline. It will do all the work with applying the transforms and making exponential inverse transformation after the prediction.
[27]:
from etna.models import CatBoostMultiSegmentModel
# Define transforms
transforms = [lags, mean, date_flags, log]
# Define a model
model = CatBoostMultiSegmentModel()
# Define a pipeline
pipeline = Pipeline(model=model, transforms=transforms, horizon=HORIZON)
# Fit the pipeline
pipeline.fit(train_ts)
# Make a forecast
forecast_ts = pipeline.forecast()
[28]:
smape(y_true=test_ts, y_pred=forecast_ts)
[28]:
{'main': 10.78610453770036}
[29]:
plot_forecast(forecast_ts=forecast_ts, test_ts=test_ts, train_ts=train_ts, n_train_samples=10)
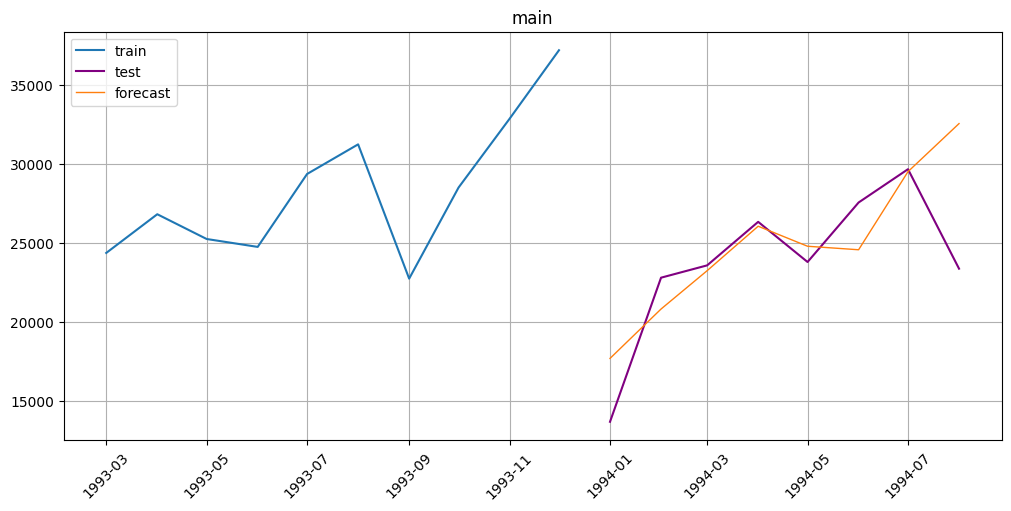
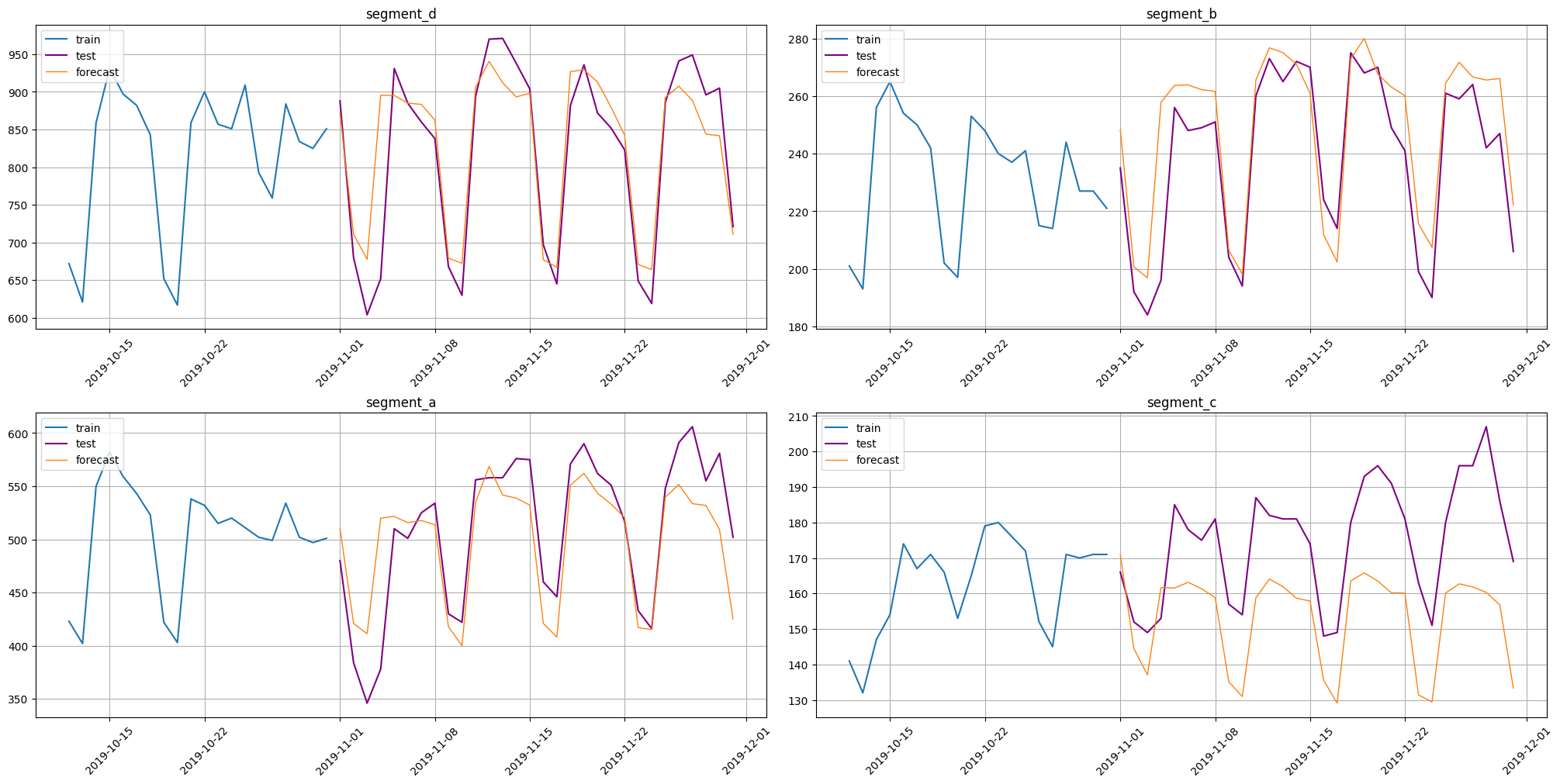
4. Forecasting multiple time series#
In this section you may see example of how easily ETNA works with multiple time series and get acquainted with other transforms the library contains.
[30]:
HORIZON = 30
[31]:
original_df = pd.read_csv("data/example_dataset.csv")
original_df.head()
[31]:
| timestamp | segment | target | |
|---|---|---|---|
| 0 | 2019-01-01 | segment_a | 170 |
| 1 | 2019-01-02 | segment_a | 243 |
| 2 | 2019-01-03 | segment_a | 267 |
| 3 | 2019-01-04 | segment_a | 287 |
| 4 | 2019-01-05 | segment_a | 279 |
[32]:
df = TSDataset.to_dataset(original_df)
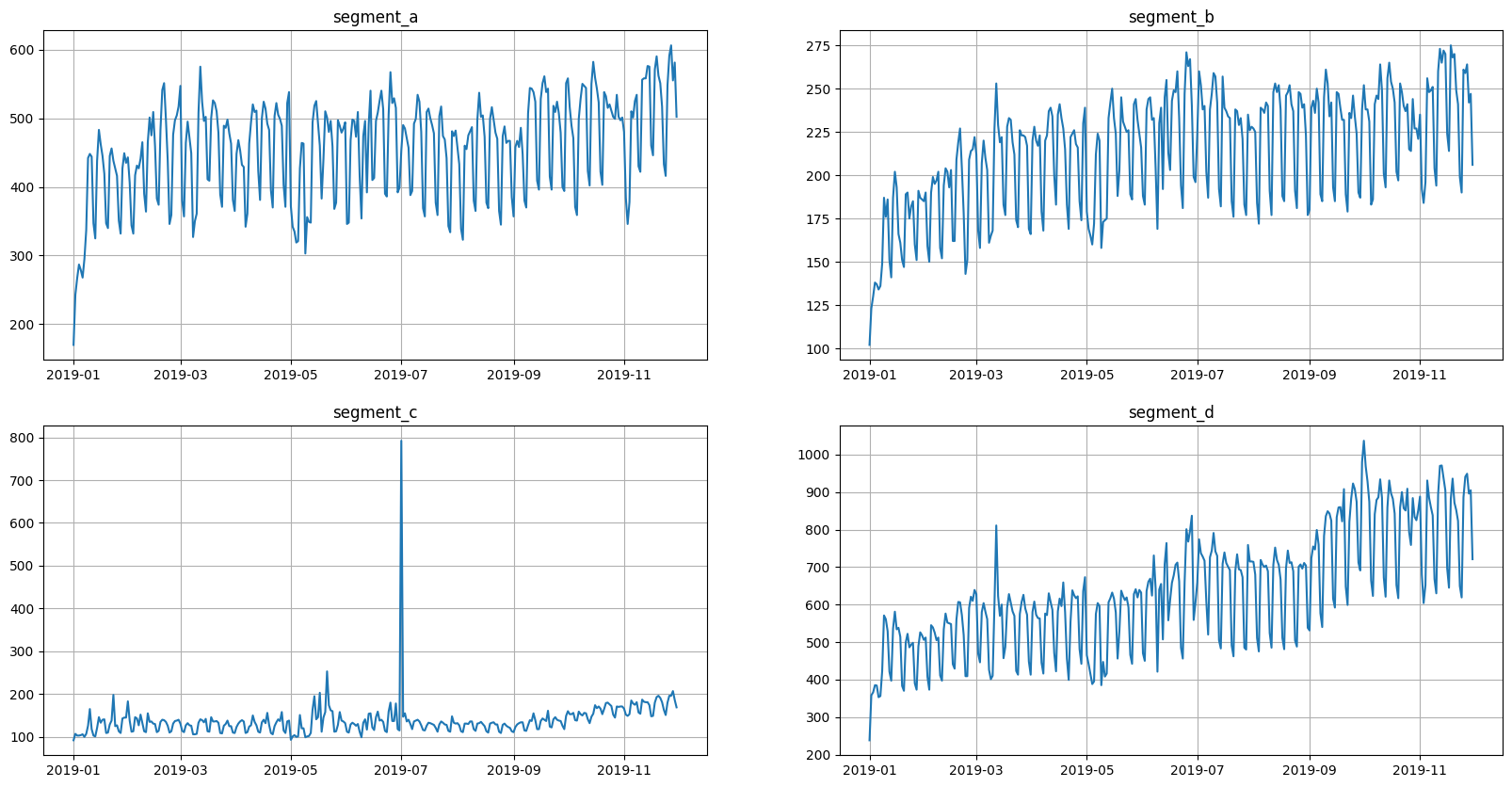
ts = TSDataset(df, freq="D")
ts.plot()
[33]:
ts.info()
<class 'etna.datasets.TSDataset'>
num_segments: 4
num_exogs: 0
num_regressors: 0
num_known_future: 0
freq: D
start_timestamp end_timestamp length num_missing
segments
segment_a 2019-01-01 2019-11-30 334 0
segment_b 2019-01-01 2019-11-30 334 0
segment_c 2019-01-01 2019-11-30 334 0
segment_d 2019-01-01 2019-11-30 334 0
[34]:
train_ts, test_ts = ts.train_test_split(test_size=HORIZON)
[35]:
test_ts.info()
<class 'etna.datasets.TSDataset'>
num_segments: 4
num_exogs: 0
num_regressors: 0
num_known_future: 0
freq: D
start_timestamp end_timestamp length num_missing
segments
segment_a 2019-11-01 2019-11-30 30 0
segment_b 2019-11-01 2019-11-30 30 0
segment_c 2019-11-01 2019-11-30 30 0
segment_d 2019-11-01 2019-11-30 30 0
[36]:
from etna.transforms import LinearTrendTransform
from etna.transforms import SegmentEncoderTransform
# Define transforms
log = LogTransform(in_column="target")
trend = LinearTrendTransform(in_column="target")
seg = SegmentEncoderTransform()
lags = LagTransform(in_column="target", lags=list(range(HORIZON, 96)), out_column="lag")
date_flags = DateFlagsTransform(
day_number_in_week=True,
day_number_in_month=True,
week_number_in_month=True,
week_number_in_year=True,
month_number_in_year=True,
year_number=True,
is_weekend=True,
)
mean = MeanTransform(in_column=f"lag_{HORIZON}", window=30)
transforms = [log, trend, lags, date_flags, seg, mean]
# Define a model
model = CatBoostMultiSegmentModel()
# Define a pipeline
pipeline = Pipeline(model=model, transforms=transforms, horizon=HORIZON)
# Fit the pipeline
pipeline.fit(train_ts)
# Make a forecast
forecast_ts = pipeline.forecast()
[37]:
smape(y_true=test_ts, y_pred=forecast_ts)
[37]:
{'segment_d': 4.705485234692143,
'segment_b': 5.1724144384125275,
'segment_a': 6.61633906776369,
'segment_c': 13.503310484019664}
[38]:
plot_forecast(forecast_ts=forecast_ts, test_ts=test_ts, train_ts=train_ts, n_train_samples=20)